AI Crawlers vs. Traditional Crawlers: How AI Indexes the Web Differently?
AI Crawlers vs. Traditional Crawlers: How AI Indexes the Web Differently?
Last Updated:
Table of Content
Title
Case Studies










Tanya Singh
Tanya Singh
GEO
GEO
12 Min Read
12 Min
In today’s digital age, when you ask a question to ChatGPT, Bard, or another AI assistant and get an instant answer, one of the unsung heroes behind the scenes is the web crawler — especially the new generation of AI-powered bots.
The new generation of AI-powered bots is roaming the web, understanding and gathering website data for the training of models with machine learning and powering of AI tools. Nevertheless, how do they work exactly? And what makes them distinct from the conventional components of search engines used by AI technology? Let us clarify all the confusion.
What is a Web Crawler and How is an AI Crawler Different?
A web crawler (by other names: spider or bot) is a program that makes a round of websites, follows links, and extracts information from pages. The main purpose of crawling done by Googlebot and similar applications was indexing the web and assisting users to get relevant search results.
But these AI crawlers are already one hatua cumbersome process back. These processors don’t just sweep in and take away the content— they comprehend it. They are able to draw richer data, recognize the surroundings, and even determine the intent through the use of NLP (natural language processing).
Let’s take a quick look at the comparison:
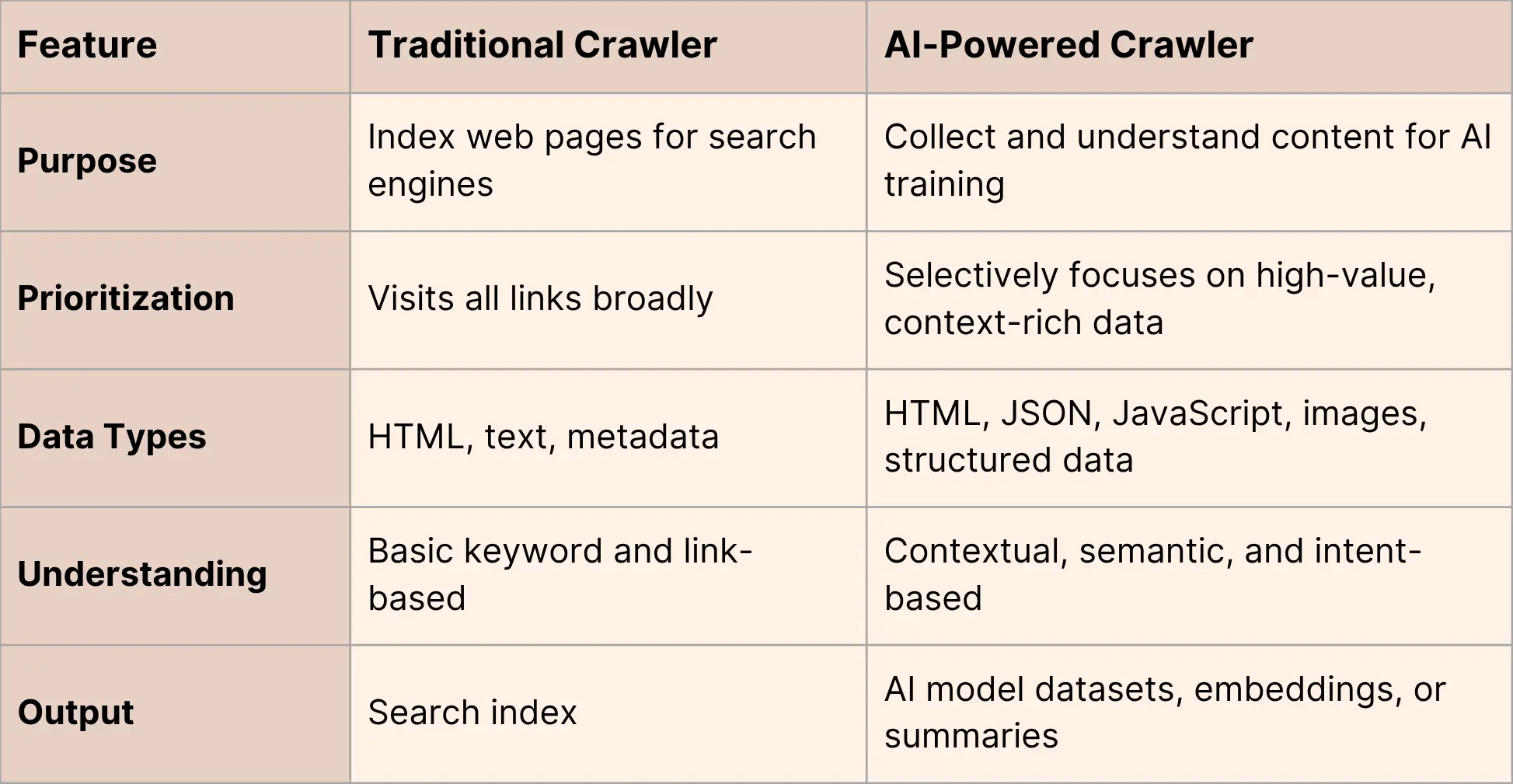
Traditional crawlers: Collect text, links, and metadata (meta titles and meta descriptions) to generate search indexes.
AI crawlers: Collect diverse data like JSON, JavaScript, and structured content while analyzing meaning and relevance.
AI bots are shaping how information is discovered, processed, and used in the modern internet—especially for generative AI and large language models (LLMs).
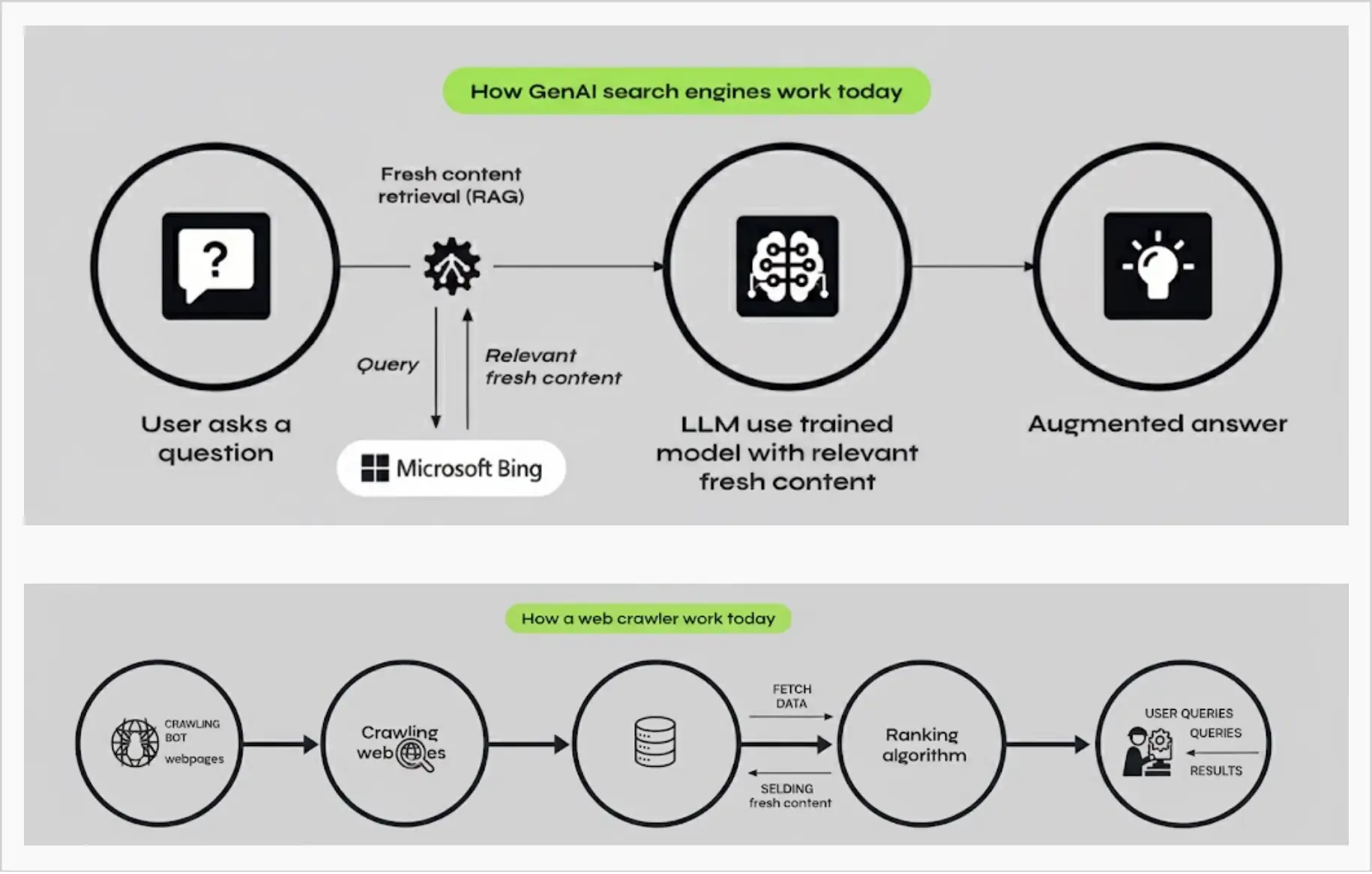
AI Crawlers: Should You Block Them or Not?
With the rise of AI-generated content and search experiences, the website owners now need to ask a different question:
To block AI crawlers or not, that is the question!
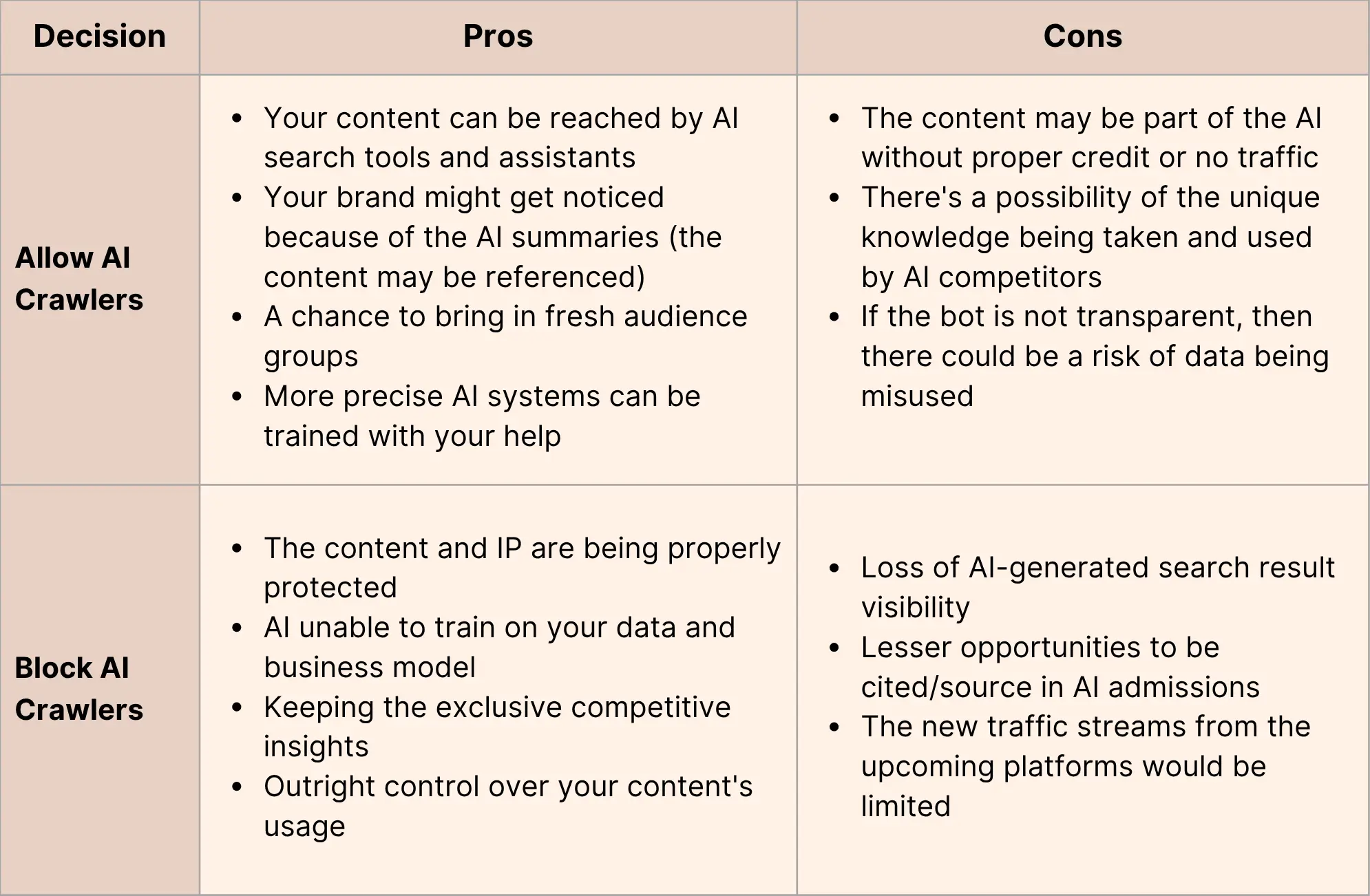
The answer will be different according to your goals. Not every web page gets the same advantage. While some of the businesses, together with the AI traffic, want to be visible and drive traffic, others intend to keep their content under lock so that it’s not used without permission.
It has become a norm, if not a standard, to block AI bots, with major publishers like The New York Times and CNN already coordinating together to limit AI crawlers’ access so that their intellectual property is protected.
On the other hand, smaller brands and new websites may depend on the exposure generated by AI-driven platforms.
In the end, this is by no means a straightforward call; it implies control, visibility, and the need for a competitive edge to be balanced.
Pros and Cons of Allowing (or Blocking) AI Crawlers
How AI Crawling Process Works?
Although the aim varies, both conventional and AI crawlers stick to a general procedure. Let us see the details of the process.
a) Discovery & URL Frontier: The crawlers begin their activity from a list of seed URLs. The seed URLs are put on a "frontier" — a list of pages to visit. AI crawlers use clever algorithms to determine which pages should be visited first, considering their freshness, domain authority, or relevance.
b) Fetching / Visiting: The crawler makes a request to the server of the website, gets the page, and then retrieves HTML, CSS, images, and scripts. Some high-tech crawlers even render JavaScript-heavy pages like a web browser does.
c) Parsing & Data Extraction: After the page has been fetched, the crawler inspects the content of the page, which includes text, links, metadata, and other data. AI-based bots are able to do more than that—they use Natural Language Processing (NLP) to grasp topics, intent, and relationships between entities.
d) Link Extraction & Queueing: The crawler detects the links that are found on the page and, in doing so, adds them to its queue, thus increasing the area of its exploration (this indicates how internal linkings are important). This is how the bots practically "follow" the internet.
e) Indexing / Storage / Learning: Normal crawlers save the text along with the metadata into a searchable index. In contrast, AI crawlers keep the data in the form of embeddings or structured datasets used for the training and fine-tuning of AI models.
f) Prioritization & Filtering: AI bots prioritize the content that is of high quality, unique, or relevant to the topic while discarding the duplicates, spam, or thin content. They rely on machine learning to determine what is valuable.

Real-World Examples of Crawlers in Action
Example 1: Search Engine Crawler
Googlebot visits a website, downloads pages, and indexes them so they appear in search results when someone searches for related terms.
Example 2: AI Training Crawler
A company that specializes in artificial intelligence is developing a model for medical research by using crawlers to scrape thousands of journal websites, extract unstructured and structured text from the sites, and train the model to respond to health-based inquiries.
Example 3: Competitive Monitoring
An eCommerce brand uses an AI-enabled crawler to watch competitors’ product prices. The bot visits competitor product pages, extracts pricing and stock information from the page, and updates the brand's internal dashboard for pricing in real-time.

Clearly, the types of crawlers are very different and AI can evolve their functionality on the base of the use case: either for search, knowledge building, or data monitoring.
The Importance of AI Crawlers for Website Owners
For anyone that owns or runs a website, it’s important to know how crawlers work for the following reasons:
Visibility and Reach: If your site is structured properly and friendly to crawlers, it is more likely to be included in AI datasets or in search indexes.
Data Use and Rights: Some AI crawlers take data simply to train their model. You may want to limit or control this activity to protect proprietary content.
Performance Impact: Crawlers that are very active on your site can place a load on your servers and increase your bandwidth usage.
Privacy: If you have a website with user-generated content, ensure that you are not exposing personally identifiable information to bots.
Traditional vs AI Crawlers — Key Differences
How to Optimize Your Site for AI and Search Crawlers?
✅ Make It Crawler-Friendly
Use clear site architecture and logical navigation.
Include a sitemap and use clean, descriptive URLs.
Add meta tags, alt text, and schema markup (structured data).
Ensure your site loads fast and is mobile-responsive.
⚠️ Manage Crawler Activity
Monitor web server logs to track bot behavior.
Limit crawl rates if your server gets too many requests.
📌 Decide Your AI Policy
If you’re open to AI bots learning from your content, keep access open.
If you prefer to restrict use for model training, block known AI crawlers.

The Future of AI Crawling
Crawling technology is evolving quickly. Some of the emerging trends include:
Intent-based crawling: Bots that decide what to crawl based on user intent or topic demand.
Adaptive crawling: AI crawlers that dynamically decide which pages to revisit or skip.
Ethical crawling: Growing discussions on consent, copyright, and transparency in AI data collection.
Data monetization: Websites may soon get paid for allowing AI crawlers to use their data.
Domain-specific crawlers: AI bots specialized for certain industries, such as medicine or law.

Case Study — A Food Blogger’s Perspective
Let’s suppose that you are a food blogger who runs a recipe blog.
The downside of having a non-crawler-friendly website is that your recipes may show up in lesser searches and also might be missed by the AI assistants.
On the other hand, when you employ structured data (such as Schema), content optimization, and descriptive metadata, it becomes much easier for AI crawlers to understand your content, e.g., finding ingredients, durations, and steps. You could allow text crawling but block access to high-quality images so that your visuals are protected. Crawler access management gives you both visibility and protection.
How to Control AI Crawlers Using Robots.txt and HTTP Headers?
Understanding crawling is one thing, and controlling it is another. Here is how you can regulate AI bot access.
a) Using Robots.txt
The robots.txt file tells crawlers what they can or can’t do. It sits in your site’s root folder (e.g., www.example.com/robots.txt).
Allow all bots

Block all bots

Allow search engines but block AI crawlers
Restrict certain folders

b) Using HTTP Headers
If you want to stop AI systems from using your content for training, you can add this header to your website:

In Apache (.htaccess):
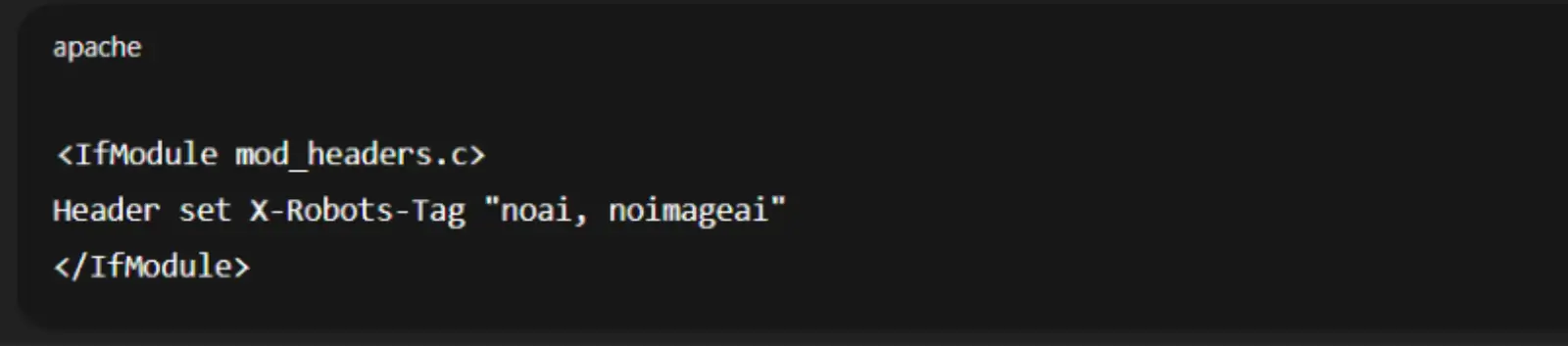
This prevents AI crawlers from using your text or images in model training.
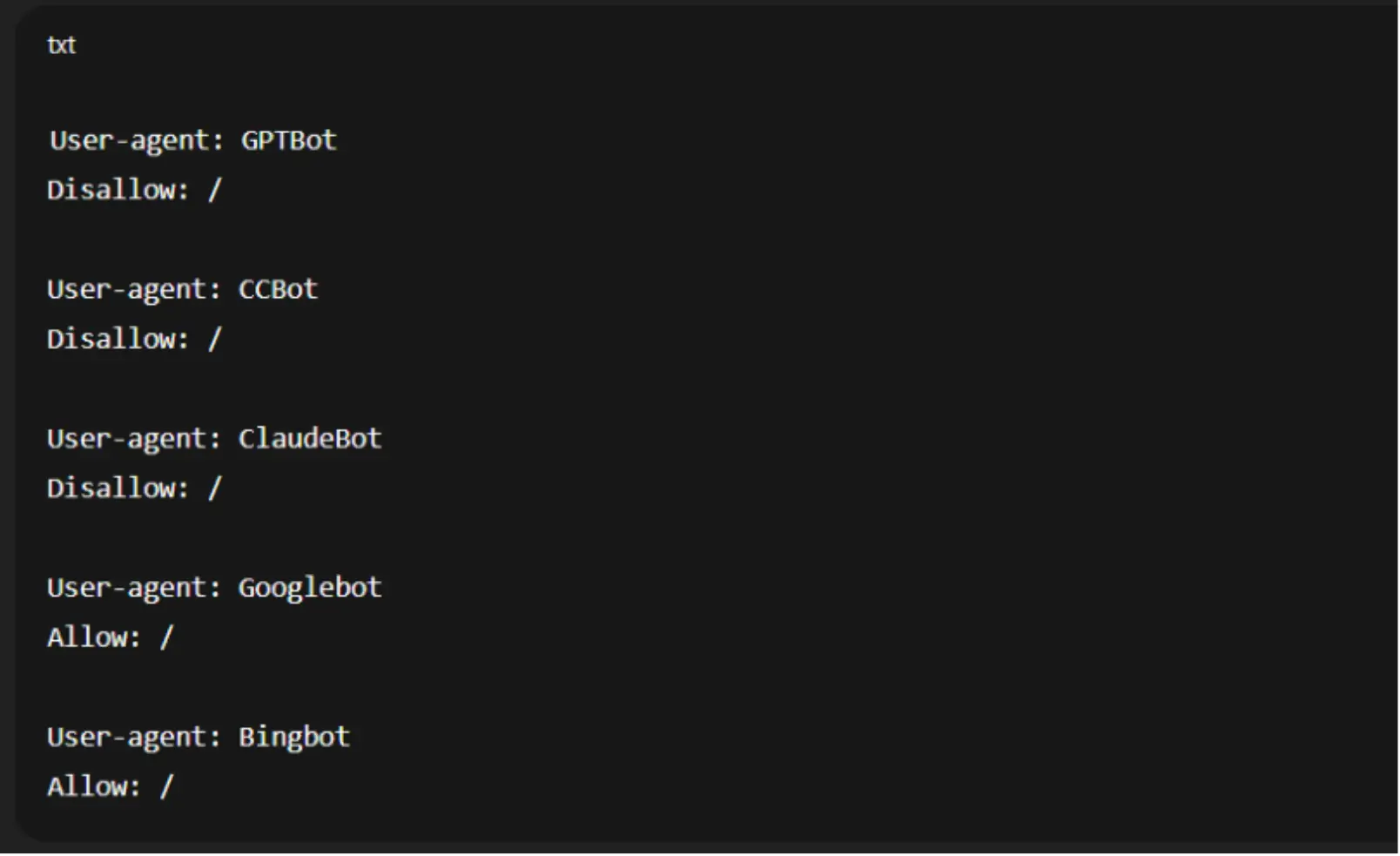
C) Common AI Crawler User-Agents
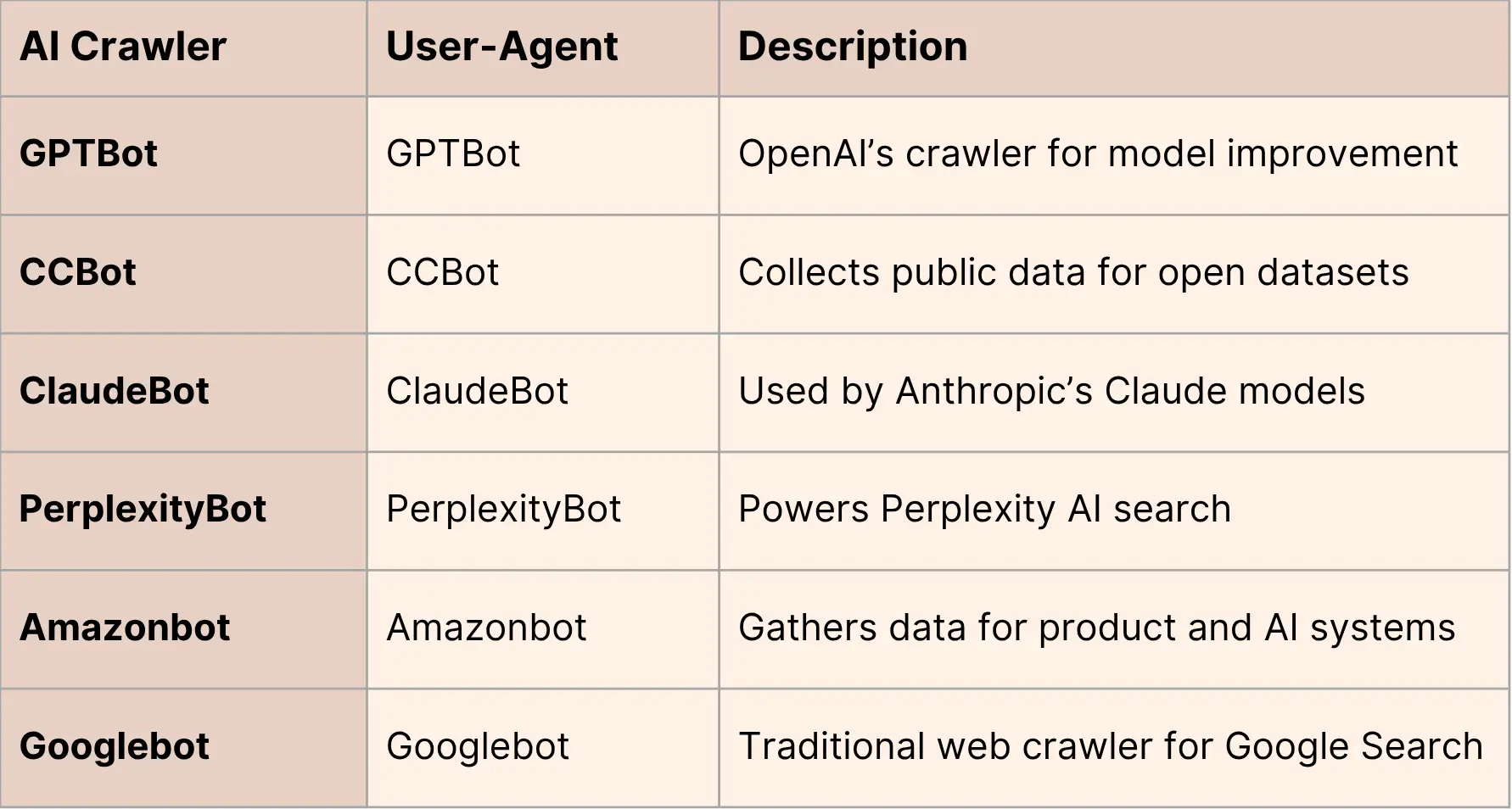
D) Best Practices
Before making changes to your site, test your robots.txt file.
Examine logs to find out which bots visit your site.
Clarify your data handling practices in your privacy policy.
As new AI bots come out, keep your rules updated.
Controlling crawler access allows you to decide how your data interacts with the AI world, either in a larger or a safer manner.
Final Thoughts
The crawling industry is moving very fast. The web crawlers are no more just the ones responsible for indexing—they are also the ones responsible for understanding.
The AI bots now have the capability to learn from the websites, to interpret the meaning, and to use this knowledge for question-answering, content summarization, and even training models.
This transformation for the content creators and companies is very clear: your content has gained the highest value.
Optimize your website for AI-driven discovery, interpretation, and visibility. Get in touch with us today to future-proof your content for the next generation of search and AI bots.
FAQs
What is the difference between search engine crawlers and AI crawlers?

Googlebot and its cousins are mostly grabbing text, links, and metadata, enough to build a search index. AI crawlers do more with that same page. They run it through NLP to work out what it actually means, what the user's probably trying to find, and how different sections connect. Instead of just filing it away as an index entry, it gets stored as structured data or embeddings the model can actually reason over later.
Should I block AI crawlers from my website?
How does robots.txt control AI crawler access?
What makes content easier for AI crawlers to understand?
Can blocking AI crawlers hurt my traffic?
In today’s digital age, when you ask a question to ChatGPT, Bard, or another AI assistant and get an instant answer, one of the unsung heroes behind the scenes is the web crawler — especially the new generation of AI-powered bots.
The new generation of AI-powered bots is roaming the web, understanding and gathering website data for the training of models with machine learning and powering of AI tools. Nevertheless, how do they work exactly? And what makes them distinct from the conventional components of search engines used by AI technology? Let us clarify all the confusion.
What is a Web Crawler and How is an AI Crawler Different?
A web crawler (by other names: spider or bot) is a program that makes a round of websites, follows links, and extracts information from pages. The main purpose of crawling done by Googlebot and similar applications was indexing the web and assisting users to get relevant search results.
But these AI crawlers are already one hatua cumbersome process back. These processors don’t just sweep in and take away the content— they comprehend it. They are able to draw richer data, recognize the surroundings, and even determine the intent through the use of NLP (natural language processing).
Let’s take a quick look at the comparison:
Traditional crawlers: Collect text, links, and metadata (meta titles and meta descriptions) to generate search indexes.
AI crawlers: Collect diverse data like JSON, JavaScript, and structured content while analyzing meaning and relevance.
AI bots are shaping how information is discovered, processed, and used in the modern internet—especially for generative AI and large language models (LLMs).
AI Crawlers: Should You Block Them or Not?
With the rise of AI-generated content and search experiences, the website owners now need to ask a different question:
To block AI crawlers or not, that is the question!
The answer will be different according to your goals. Not every web page gets the same advantage. While some of the businesses, together with the AI traffic, want to be visible and drive traffic, others intend to keep their content under lock so that it’s not used without permission.
It has become a norm, if not a standard, to block AI bots, with major publishers like The New York Times and CNN already coordinating together to limit AI crawlers’ access so that their intellectual property is protected.
On the other hand, smaller brands and new websites may depend on the exposure generated by AI-driven platforms.
In the end, this is by no means a straightforward call; it implies control, visibility, and the need for a competitive edge to be balanced.
Pros and Cons of Allowing (or Blocking) AI Crawlers
How AI Crawling Process Works?
Although the aim varies, both conventional and AI crawlers stick to a general procedure. Let us see the details of the process.
a) Discovery & URL Frontier: The crawlers begin their activity from a list of seed URLs. The seed URLs are put on a "frontier" — a list of pages to visit. AI crawlers use clever algorithms to determine which pages should be visited first, considering their freshness, domain authority, or relevance.
b) Fetching / Visiting: The crawler makes a request to the server of the website, gets the page, and then retrieves HTML, CSS, images, and scripts. Some high-tech crawlers even render JavaScript-heavy pages like a web browser does.
c) Parsing & Data Extraction: After the page has been fetched, the crawler inspects the content of the page, which includes text, links, metadata, and other data. AI-based bots are able to do more than that—they use Natural Language Processing (NLP) to grasp topics, intent, and relationships between entities.
d) Link Extraction & Queueing: The crawler detects the links that are found on the page and, in doing so, adds them to its queue, thus increasing the area of its exploration (this indicates how internal linkings are important). This is how the bots practically "follow" the internet.
e) Indexing / Storage / Learning: Normal crawlers save the text along with the metadata into a searchable index. In contrast, AI crawlers keep the data in the form of embeddings or structured datasets used for the training and fine-tuning of AI models.
f) Prioritization & Filtering: AI bots prioritize the content that is of high quality, unique, or relevant to the topic while discarding the duplicates, spam, or thin content. They rely on machine learning to determine what is valuable.
Real-World Examples of Crawlers in Action
Example 1: Search Engine Crawler
Googlebot visits a website, downloads pages, and indexes them so they appear in search results when someone searches for related terms.
Example 2: AI Training Crawler
A company that specializes in artificial intelligence is developing a model for medical research by using crawlers to scrape thousands of journal websites, extract unstructured and structured text from the sites, and train the model to respond to health-based inquiries.
Example 3: Competitive Monitoring
An eCommerce brand uses an AI-enabled crawler to watch competitors’ product prices. The bot visits competitor product pages, extracts pricing and stock information from the page, and updates the brand's internal dashboard for pricing in real-time.
Clearly, the types of crawlers are very different and AI can evolve their functionality on the base of the use case: either for search, knowledge building, or data monitoring.
The Importance of AI Crawlers for Website Owners
For anyone that owns or runs a website, it’s important to know how crawlers work for the following reasons:
Visibility and Reach: If your site is structured properly and friendly to crawlers, it is more likely to be included in AI datasets or in search indexes.
Data Use and Rights: Some AI crawlers take data simply to train their model. You may want to limit or control this activity to protect proprietary content.
Performance Impact: Crawlers that are very active on your site can place a load on your servers and increase your bandwidth usage.
Privacy: If you have a website with user-generated content, ensure that you are not exposing personally identifiable information to bots.
Traditional vs AI Crawlers — Key Differences
How to Optimize Your Site for AI and Search Crawlers?
✅ Make It Crawler-Friendly
Use clear site architecture and logical navigation.
Include a sitemap and use clean, descriptive URLs.
Add meta tags, alt text, and schema markup (structured data).
Ensure your site loads fast and is mobile-responsive.
⚠️ Manage Crawler Activity
Monitor web server logs to track bot behavior.
Limit crawl rates if your server gets too many requests.
📌 Decide Your AI Policy
If you’re open to AI bots learning from your content, keep access open.
If you prefer to restrict use for model training, block known AI crawlers.
The Future of AI Crawling
Crawling technology is evolving quickly. Some of the emerging trends include:
Intent-based crawling: Bots that decide what to crawl based on user intent or topic demand.
Adaptive crawling: AI crawlers that dynamically decide which pages to revisit or skip.
Ethical crawling: Growing discussions on consent, copyright, and transparency in AI data collection.
Data monetization: Websites may soon get paid for allowing AI crawlers to use their data.
Domain-specific crawlers: AI bots specialized for certain industries, such as medicine or law.
Case Study — A Food Blogger’s Perspective
Let’s suppose that you are a food blogger who runs a recipe blog.
The downside of having a non-crawler-friendly website is that your recipes may show up in lesser searches and also might be missed by the AI assistants.
On the other hand, when you employ structured data (such as Schema), content optimization, and descriptive metadata, it becomes much easier for AI crawlers to understand your content, e.g., finding ingredients, durations, and steps. You could allow text crawling but block access to high-quality images so that your visuals are protected. Crawler access management gives you both visibility and protection.
How to Control AI Crawlers Using Robots.txt and HTTP Headers?
Understanding crawling is one thing, and controlling it is another. Here is how you can regulate AI bot access.
a) Using Robots.txt
The robots.txt file tells crawlers what they can or can’t do. It sits in your site’s root folder (e.g., www.example.com/robots.txt).
Allow all bots
Block all bots
Allow search engines but block AI crawlers
Restrict certain folders
b) Using HTTP Headers
If you want to stop AI systems from using your content for training, you can add this header to your website:
In Apache (.htaccess):
This prevents AI crawlers from using your text or images in model training.
C) Common AI Crawler User-Agents
D) Best Practices
Before making changes to your site, test your robots.txt file.
Examine logs to find out which bots visit your site.
Clarify your data handling practices in your privacy policy.
As new AI bots come out, keep your rules updated.
Controlling crawler access allows you to decide how your data interacts with the AI world, either in a larger or a safer manner.
Final Thoughts
The crawling industry is moving very fast. The web crawlers are no more just the ones responsible for indexing—they are also the ones responsible for understanding.
The AI bots now have the capability to learn from the websites, to interpret the meaning, and to use this knowledge for question-answering, content summarization, and even training models.
This transformation for the content creators and companies is very clear: your content has gained the highest value.
Optimize your website for AI-driven discovery, interpretation, and visibility. Get in touch with us today to future-proof your content for the next generation of search and AI bots.
FAQs
What is the difference between search engine crawlers and AI crawlers?
Googlebot and its cousins are mostly grabbing text, links, and metadata, enough to build a search index. AI crawlers do more with that same page. They run it through NLP to work out what it actually means, what the user's probably trying to find, and how different sections connect. Instead of just filing it away as an index entry, it gets stored as structured data or embeddings the model can actually reason over later.
Should I block AI crawlers from my website?
How does robots.txt control AI crawler access?
What makes content easier for AI crawlers to understand?
Can blocking AI crawlers hurt my traffic?


Summarize with AI




Want to be seen everywhere?
Get a free AI-search audit Today!



4.9/5 Ratings!


Don’t miss our revenue growth tips!
Get expert marketing tips—straight to your inbox, like thousands of happy clients.
Don’t miss our revenue growth tips!
Get expert marketing tips—straight to your inbox, like thousands of happy clients.
Don’t miss our revenue growth tips!
Don’t miss our revenue growth tips!
Get expert marketing tips—straight to your inbox, like thousands of happy clients.
Relevant Blogs on Generative AI SEO
Relevant Blogs on Generative AI SEO
Unlock data-driven insights in AI-powered SEO—explore our featured blogs and skyrocket your revenue before your competitors do.
Unlock data-driven insights in AI-powered SEO—explore our featured blogs and skyrocket your revenue before your competitors do.

GEO
Jul 30, 2026
10 Min Read
Top 7 Generative Engine Optimization (GEO) Agencies in Houston
GEO
Jul 30, 2026
10 Min Read
Top 7 Generative Engine Optimization (GEO) Agencies in Houston
GEO
Jul 30, 2026
10 Min Read
Top 7 Generative Engine Optimization (GEO) Agencies in Houston

GEO
Jul 29, 2026
10 Min Read
Why Your Local Business Isn't Appearing in Google AI Overviews
GEO
Jul 29, 2026
10 Min Read
Why Your Local Business Isn't Appearing in Google AI Overviews
GEO
Jul 29, 2026
10 Min Read
Why Your Local Business Isn't Appearing in Google AI Overviews

GEO
Jul 27, 2026
8 Min Read
7 Things Every Medical Practice Must Have to Show Up in AI Search Recommendations in 2026
GEO
Jul 27, 2026
8 Min Read
7 Things Every Medical Practice Must Have to Show Up in AI Search Recommendations in 2026
GEO
Jul 27, 2026
8 Min Read
7 Things Every Medical Practice Must Have to Show Up in AI Search Recommendations in 2026




































Ready to speak with an expert?
Data-Driven Marketing Agency That Elevates ROI
1100+
Websites Designed & Optimized to Convert
$280M+
Client Revenue Driven & Growing Strong
Discover how to skyrocket
your revenue today!
Trusted by 1000+ Owners!
Ready to speak with an expert?
Data-Driven Marketing Agency That Elevates ROI
1100+
Websites Designed & Optimized to Convert
$280M+
Client Revenue Driven & Growing Strong
Discover how to skyrocket
your revenue today!
Trusted by 1000+ Owners!
Want to skyrocket revenue?
4.9/5 Ratings!
Ready to speak with an expert?
Data-Driven Marketing Agency That Elevates ROI
1100+
Websites Designed & Optimized to Convert
$280M+
Client Revenue Driven & Growing Strong
Want to skyrocket
revenue?
Trusted by 1000+ Owners!
Call
Meet

